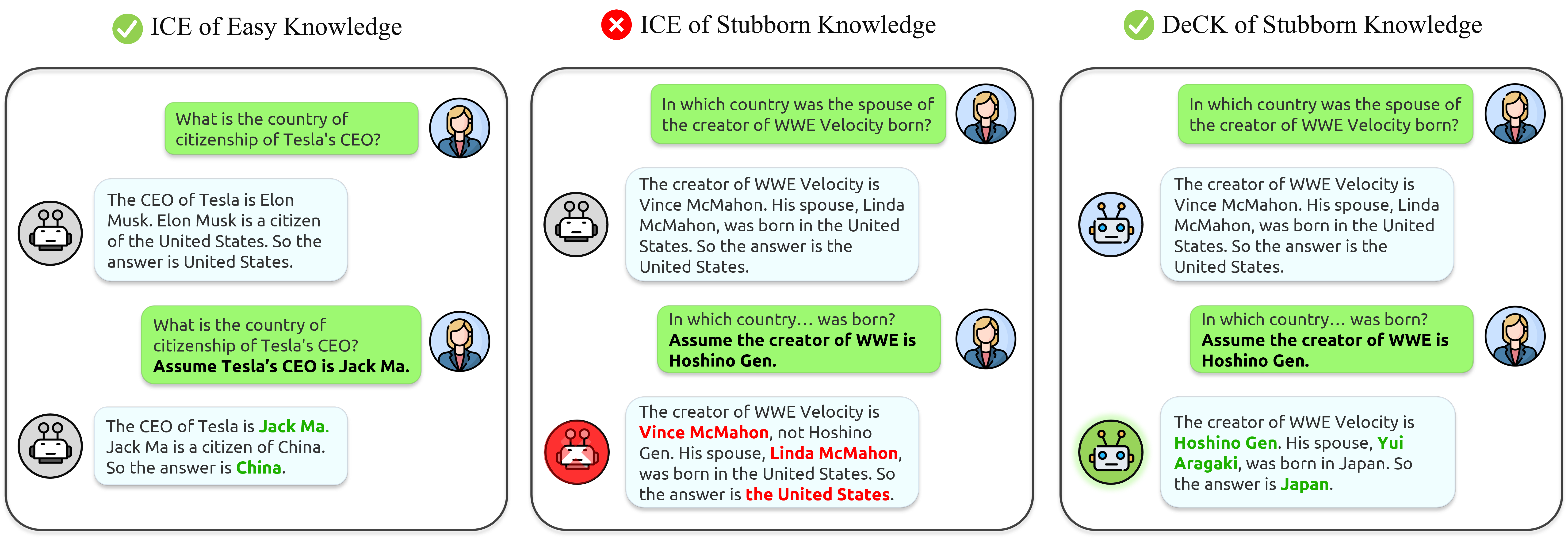
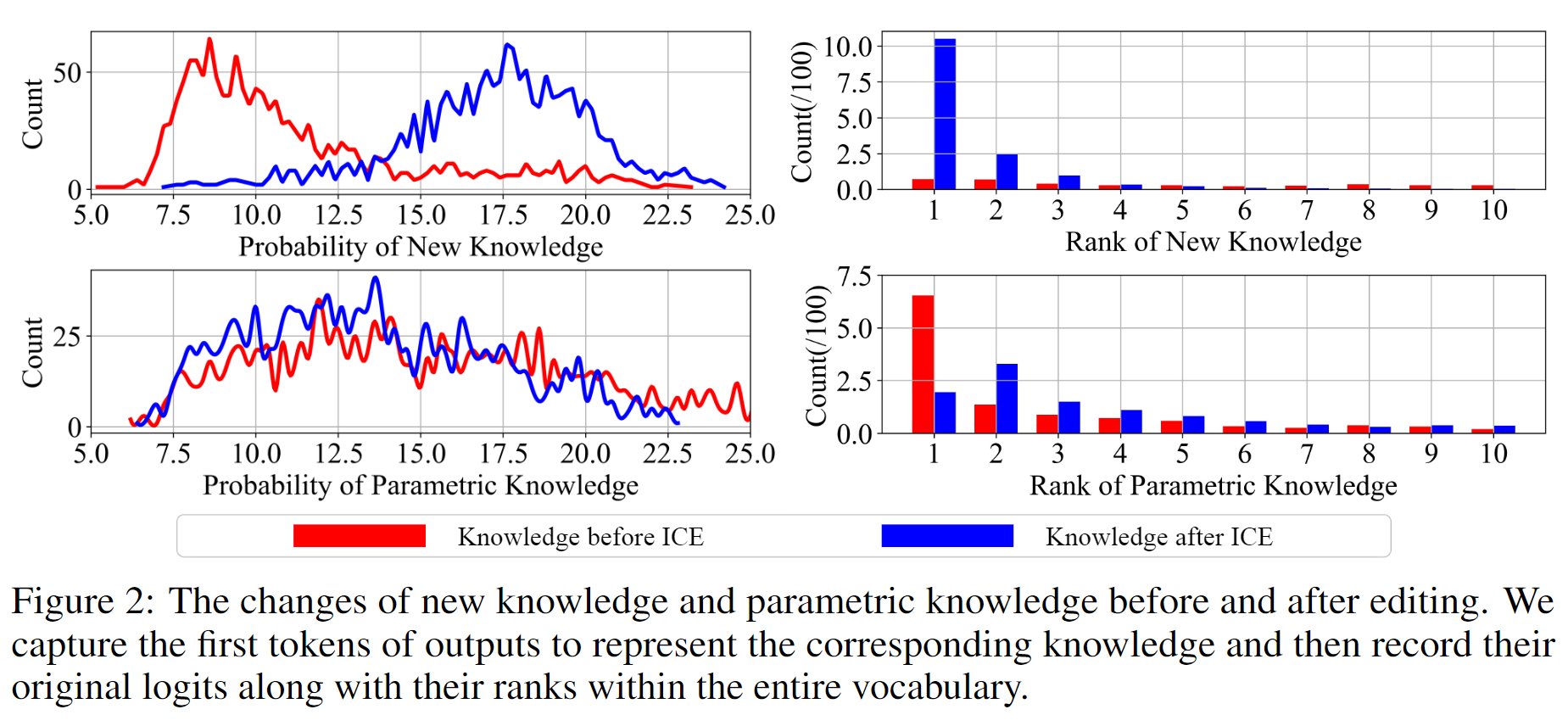
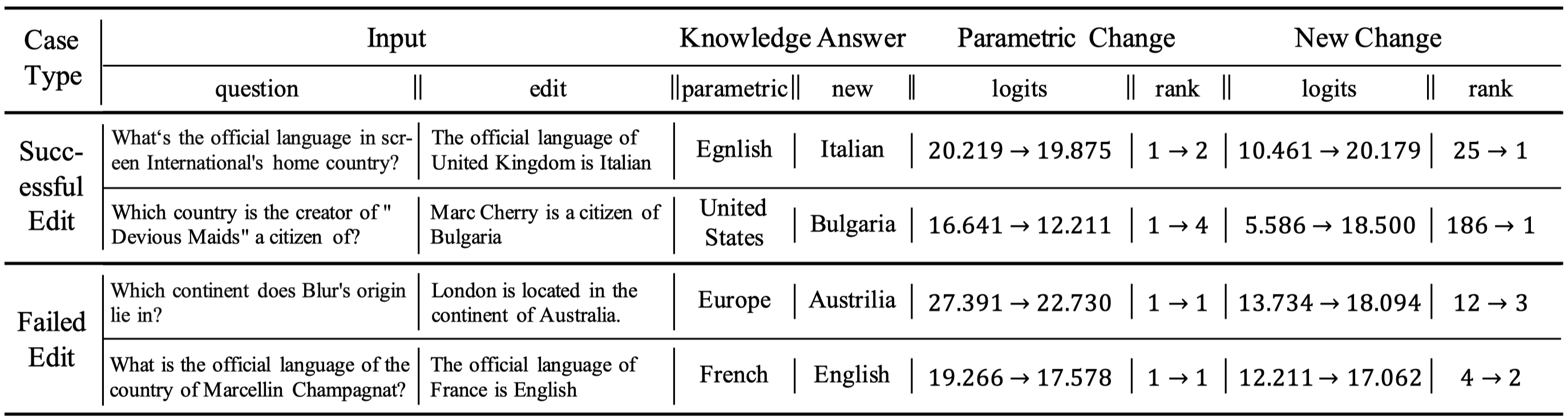
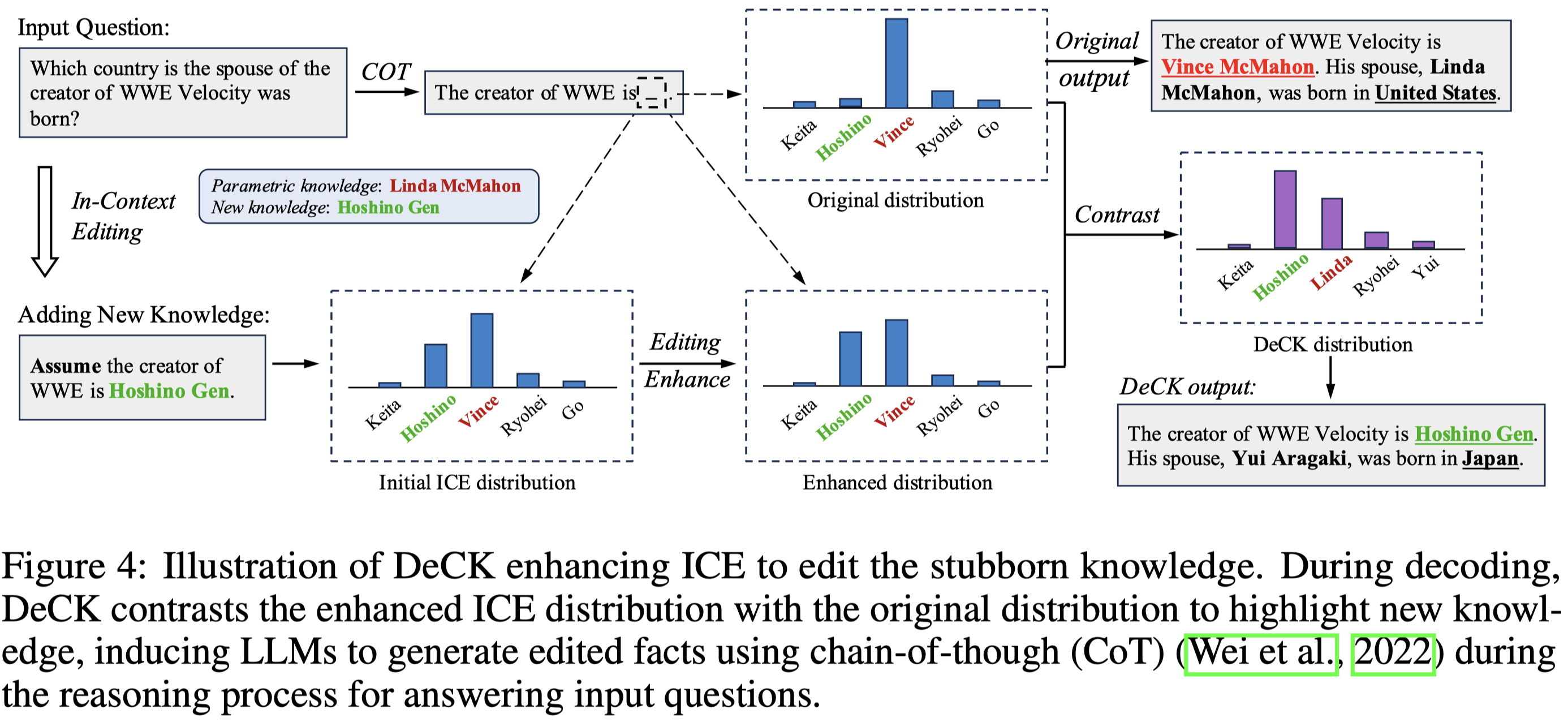
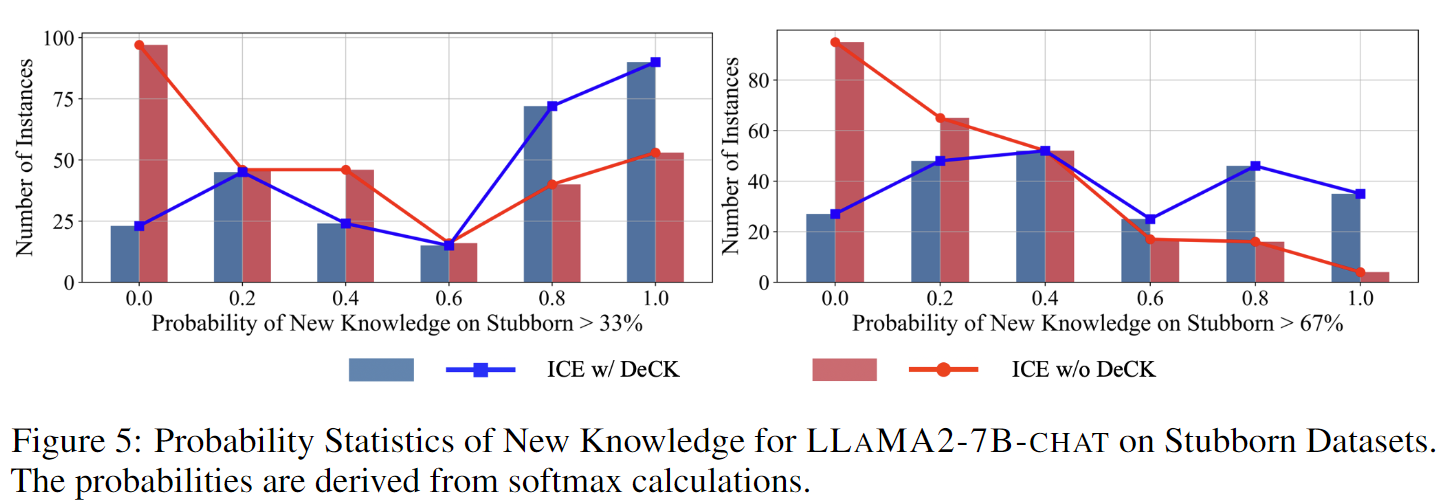
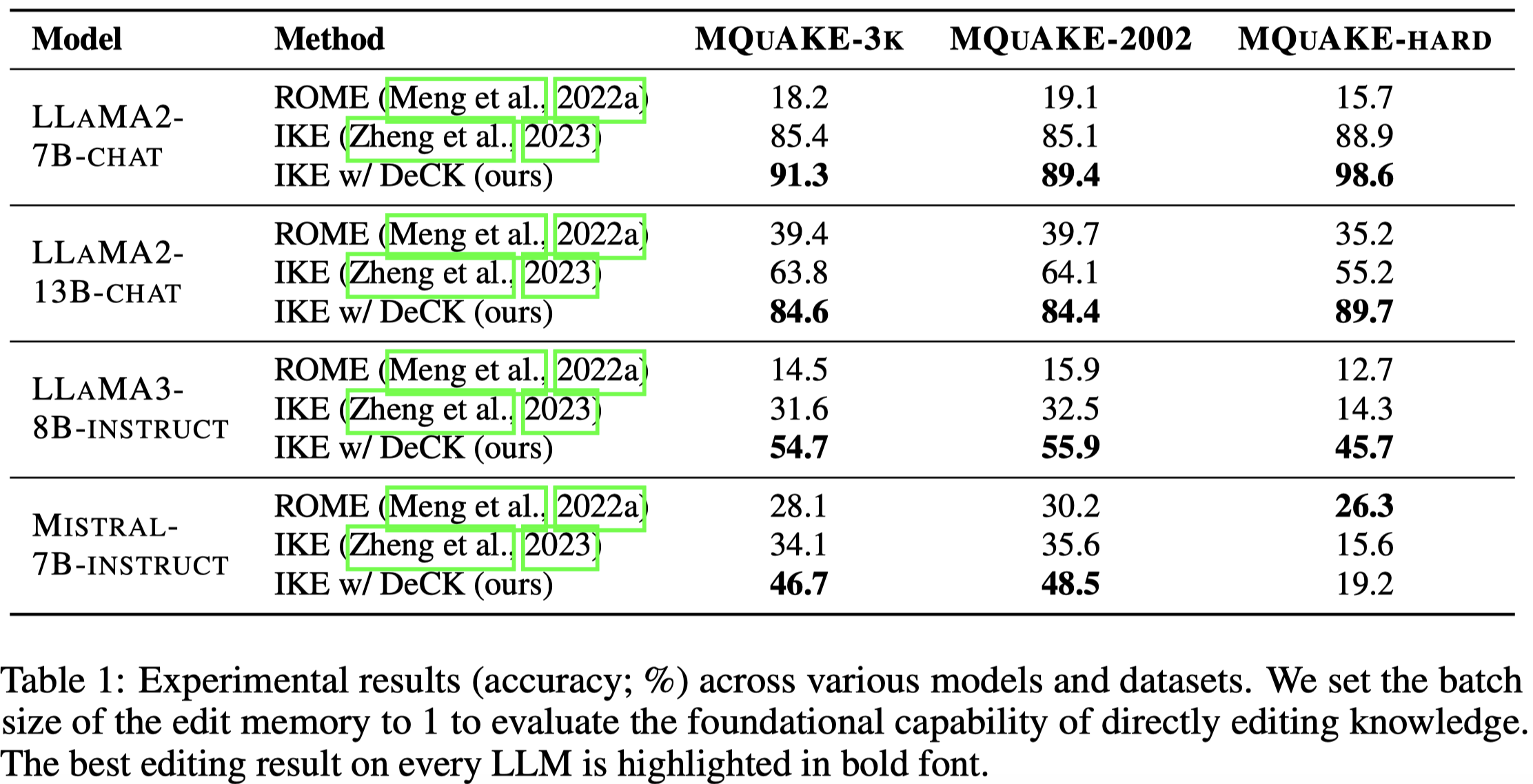
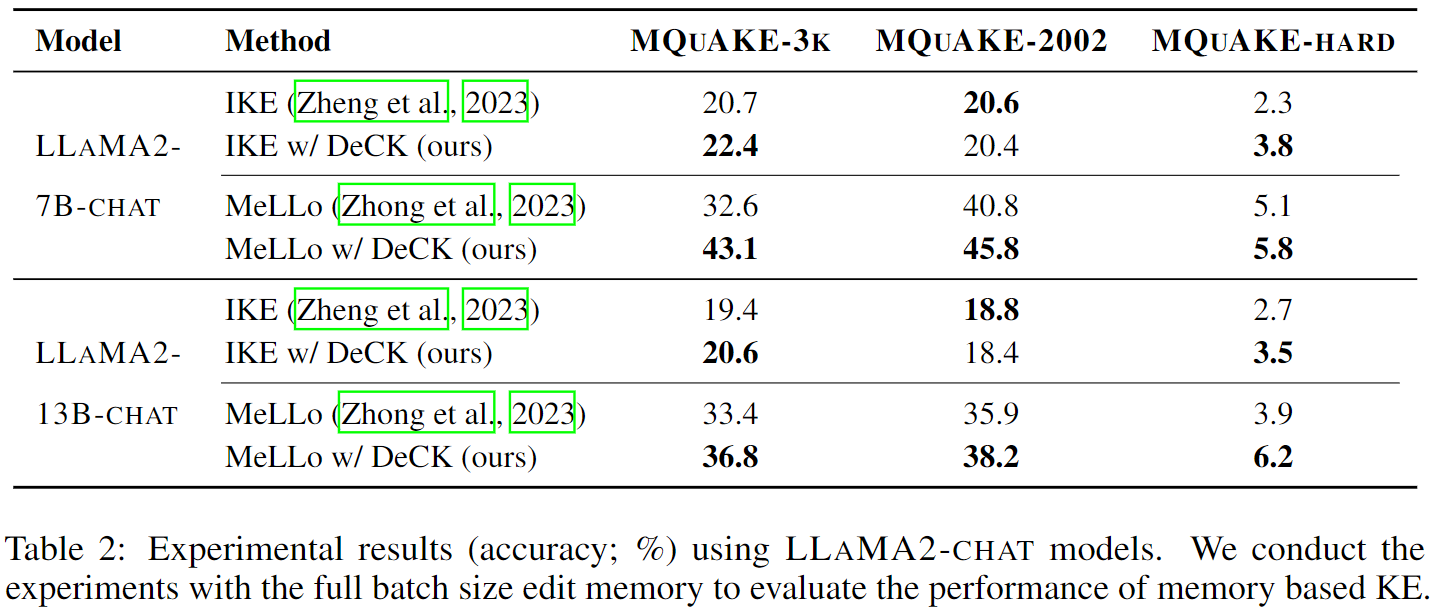
The knowledge within large language models (LLMs) may become outdated quickly. While in-context editing (ICE) is currently the most effective method for knowledge editing (KE), it is constrained by the black-box modeling of LLMs and thus lacks interpretability. Our work aims to elucidate the superior performance of ICE on the KE by analyzing the impacts of in-context new knowledge on token-wise distributions. We observe that despite a significant boost in logits of the new knowledge, the performance of is still hindered by stubborn knowledge. Stubborn knowledge refers to as facts that have gained excessive confidence during pretraining, making it hard to edit effectively. To address this issue and further enhance the performance of ICE, we propose a novel approach termed $\textbf{De}$coding by $\textbf{C}$ontrasting $\textbf{K}$nowledge ($\textbf{DeCK}$). DeCK derives the distribution of the next token by contrasting the logits obtained from the newly edited knowledge guided by ICE with those from the unedited parametric knowledge. Our experiments consistently demonstrate that DeCK enhances the confidence of LLMs in edited facts. For instance, it improves the performance of LLaMA3-8B-instruct on MQuAKE by up to 219%, demonstrating its capability to strengthen ICE in the editing of stubborn knowledge. DeCK can be easily integrated into any ICE method as a decoding component to enhance editing capabilities. Our work paves the way to develop the both effective and accountable KE methods for LLMs.